Sedert sy openbare bekendstelling 10 jaar gelede, is Twitter gebruik as 'n sosiale netwerkplatform onder vriende, 'n kitsboodskapdiens vir slimfoongebruikers en 'n promosie-instrument vir korporasies en politici.
Maar dit was ook 'n waardevolle bron van data vir navorsers en wetenskaplikes - soos ek - wat wil studeer hoe mense binne komplekse sosiale sisteme voel en funksioneer.
Deur tweets te analiseer, is ons in staat om data oor die sosiale interaksies van miljoene mense "in die wild" buite beheerde laboratorium eksperimente in ag te neem en te versamel.
Dit het ons in staat gestel om gereedskap te ontwikkel vir die monitering van die kollektiewe emosies van groot bevolkings, vind die gelukkigste plekke in die Verenigde State en nog baie meer.
So hoe het Twitter so 'n unieke hulpbron geword vir rekenkundige sosiale wetenskaplikes? En wat het ons toegelaat om te ontdek?

Twitter se grootste geskenk aan navorsers
Op Julie 15, 2006, Twittr (soos dit destyds bekend was) openbaar van stapel gestuur as 'n "mobiele diens wat groepe vriende help om willekeurige gedagtes rond te smoor met SMS." Die vermoë om gratis 140-karaktergroeptekste te stuur, het baie vroeë adopters (myself ingesluit) gebruik om die platform te gebruik.
Met die tyd, die aantal gebruikers ontplof: van 20 miljoen in 2009 tot 200 miljoen in 2012 en 310 miljoen vandag. Eerder as om direk met vriende te kommunikeer, sal gebruikers eenvoudig hul volgelinge vertel hoe hulle gevoel het, positief of negatief op nuus reageer of grappies kraak.
Vir navorsers is Twitter se grootste geskenk die voorsiening van groot hoeveelhede oop data. Twitter was een van die eerste groot sosiale netwerke om data-monsters te verskaf deur middel van toepassingsprogrammeringskoppelvlakke (API's), wat navorsers in staat stel om Twitter te vra vir spesifieke tipes tweets (bv. Tweets wat sekere woorde bevat), sowel as inligting oor gebruikers .
Dit het gelei tot 'n ontploffing van navorsingsprojekte wat hierdie data gebruik. Vandag, 'n Google Wetenskap-soektog vir "Twitter" produseer ses miljoen treffers, in vergelyking met vyf miljoen vir "Facebook." Die verskil is veral opvallend, aangesien Facebook rofweg vyf keer soveel gebruikers as Twitter (en is twee jaar ouer).
Twitter se vrygewige databeleid het ongetwyfeld gelei tot 'n paar uitstekende gratis publisiteit vir die maatskappy, aangesien interessante wetenskaplike studies deur die hoofstroommedia opgetel is.
Studeer geluk en gesondheid
Met tradisionele sensusdata stadig en duur om te versamel, maak data feeds soos Twitter die potensiaal om 'n real-time venster te gee om veranderinge in groot populasies te sien.
Die Universiteit van Vermont se Computational Story Lab is gestig in 2006 en studeer probleme oor toegepaste wiskunde, sosiologie en fisika. Sedert 2008 het die Story Lab biljoene tweets versamel deur Twitter se "Gardenhose" -toevoer, 'n API wat in reële tyd 'n ewekansige steekproef van 10 persentasie van alle publieke tweets stroom.
Ek het drie jaar by die rekenaarsverhaallaboratorium deurgebring en was gelukkig om deel te wees van baie interessante studies met behulp van hierdie data. Byvoorbeeld, ons het 'n hedonometer wat meet die geluk van die Twittersphere in real time. Deur te fokus op geolocated tweets gestuur vanaf slimfone, was ons in staat om kaart die gelukkigste plekke in die Verenigde State. Miskien het ons dit nie verrassend gevind nie Hawaii is die gelukkigste staat en wynbouende Napa, die gelukkigste stad vir 2013.
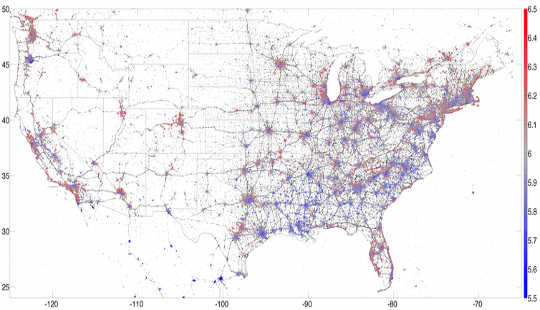 'N kaart van 13 miljoen geolocated Amerikaanse tweets van 2013, met geluk gekleur, met rooi aanduiding geluk en blou aanduiding verdriet. PLoS ONE, Outeur verskaf.Hierdie studies het dieper aansoeke gehad: Korrelerende Twitter-woordgebruik met demografie het ons gehelp om onderliggende sosio-ekonomiese patrone in stede te verstaan. Byvoorbeeld, ons kon die woordgebruik met gesondheidsfaktore soos vetsug skakel, dus het ons 'n lexicocalorimeter Om die "kalorie-inhoud" van sosiale media-poste te meet. Tweets uit 'n bepaalde streek wat hoë-kalorie-kosse genoem het, het die "kalorie-inhoud" van daardie streek verhoog, terwyl tweets wat oefenaktiwiteite genoem het, ons metriek verlaag het. Ons het gevind dat hierdie eenvoudige maatreël korreleer met ander gesondheids- en welstandsmetrie. Met ander woorde, tweets was in staat om ons 'n momentopname te gee op 'n spesifieke tydstip van die algemene gesondheid van 'n stad of streek.
'N kaart van 13 miljoen geolocated Amerikaanse tweets van 2013, met geluk gekleur, met rooi aanduiding geluk en blou aanduiding verdriet. PLoS ONE, Outeur verskaf.Hierdie studies het dieper aansoeke gehad: Korrelerende Twitter-woordgebruik met demografie het ons gehelp om onderliggende sosio-ekonomiese patrone in stede te verstaan. Byvoorbeeld, ons kon die woordgebruik met gesondheidsfaktore soos vetsug skakel, dus het ons 'n lexicocalorimeter Om die "kalorie-inhoud" van sosiale media-poste te meet. Tweets uit 'n bepaalde streek wat hoë-kalorie-kosse genoem het, het die "kalorie-inhoud" van daardie streek verhoog, terwyl tweets wat oefenaktiwiteite genoem het, ons metriek verlaag het. Ons het gevind dat hierdie eenvoudige maatreël korreleer met ander gesondheids- en welstandsmetrie. Met ander woorde, tweets was in staat om ons 'n momentopname te gee op 'n spesifieke tydstip van die algemene gesondheid van 'n stad of streek.
Met behulp van die rykdom van Twitter data, het ons ook daarin geslaag om sien mense se daaglikse bewegingspatrone in ongekende detail. Die begrip van menslike mobiliteitspatrone het op sy beurt die vermoë om siektemodellering te transformeer, die nuwe veld van digitale epidemiologie.
Vir ander studies het ons gekyk of reisigers meer geluk op Twitter uitdruk as dié wat tuis bly (antwoord: hulle doen) en indien gelukkige individue is geneig om bymekaar te bly in 'n sosiale netwerk (weer, hulle doen). Inderdaad, Positiwiteit blyk in die taal self gebak te word, in die sin dat ons meer positiewe woorde as negatiewe woorde het. Dit was nie net op Twitter nie, maar ook oor 'n verskeidenheid verskillende media (bv. Boeke, flieks en koerante) en tale.
Hierdie studies - en duisende ander soos hulle van regoor die wêreld - was slegs moontlik danksy Twitter.
Die volgende 10 jaar
So, wat kan ons van Twitter verwag oor die volgende 10-jare?
Sommige van die opwindendste werk behels tans die koppeling van sosiale media-data met wiskundige modelle om bevolkingsvlakverskynsels soos siekteuitbrake te voorspel. Navorsers het reeds 'n bietjie sukses gehad om siektemodelle met Twitter-data te verbeter om griep voor te stel, veral die FluOutlook platform ontwikkel deur die Noordoostelike Universiteit en die Instituut vir Wetenskaplike Uitruiling.
Tog bly 'n aantal uitdagings. Sosiale media data ly aan 'n baie lae "sein-tot-ruis verhouding". Met ander woorde, die tweets wat relevant is vir 'n bepaalde studie word dikwels verdrink deur irrelevante "geraas".
Daarom moet ons voortdurend bewus wees van wat genoem word "groot data hubris"Wanneer ons nuwe metodes ontwikkel en nie ons resultate oortuig nie. Verband met hierdie moet die doel wees om voorspellings uit hierdie data te interpreteerbare (glasbokse) voorspellings (in teenstelling met "black box" voorspellings, waarin die algoritme weggesteek of onduidelik is).
Sosiale media data word dikwels (redelik) gekritiseer omdat hulle 'n klein, nie-verteenwoordigende steekproef van die breër bevolking. Een van die groot uitdagings vir navorsers is om uit te vind hoe om sulke skeefde data in statistiese modelle te verantwoord. terwyl meer mense gebruik elke jaar sosiale media, moet ons voortgaan om die vooroordele in hierdie data te verstaan. Byvoorbeeld, die data is geneig om selfs jonger individue te oorverteenwoordig ten koste van ouer bevolkings.
Eers ná die ontwikkeling van beter vooroordeel-regstelling metodes sal navorsers vol vertroue voorspellings van tweets kan maak.
Oor Die Skrywer
Lewis Mitchell, Dosent in Toegepaste Wiskunde, Universiteit van Adelaide
Hierdie artikel is oorspronklik gepubliseer op Die gesprek. Lees die oorspronklike artikel.
verwante Boeke
at InnerSelf Market en Amazon